۱۰. مشکل Resource Quota exceeded:
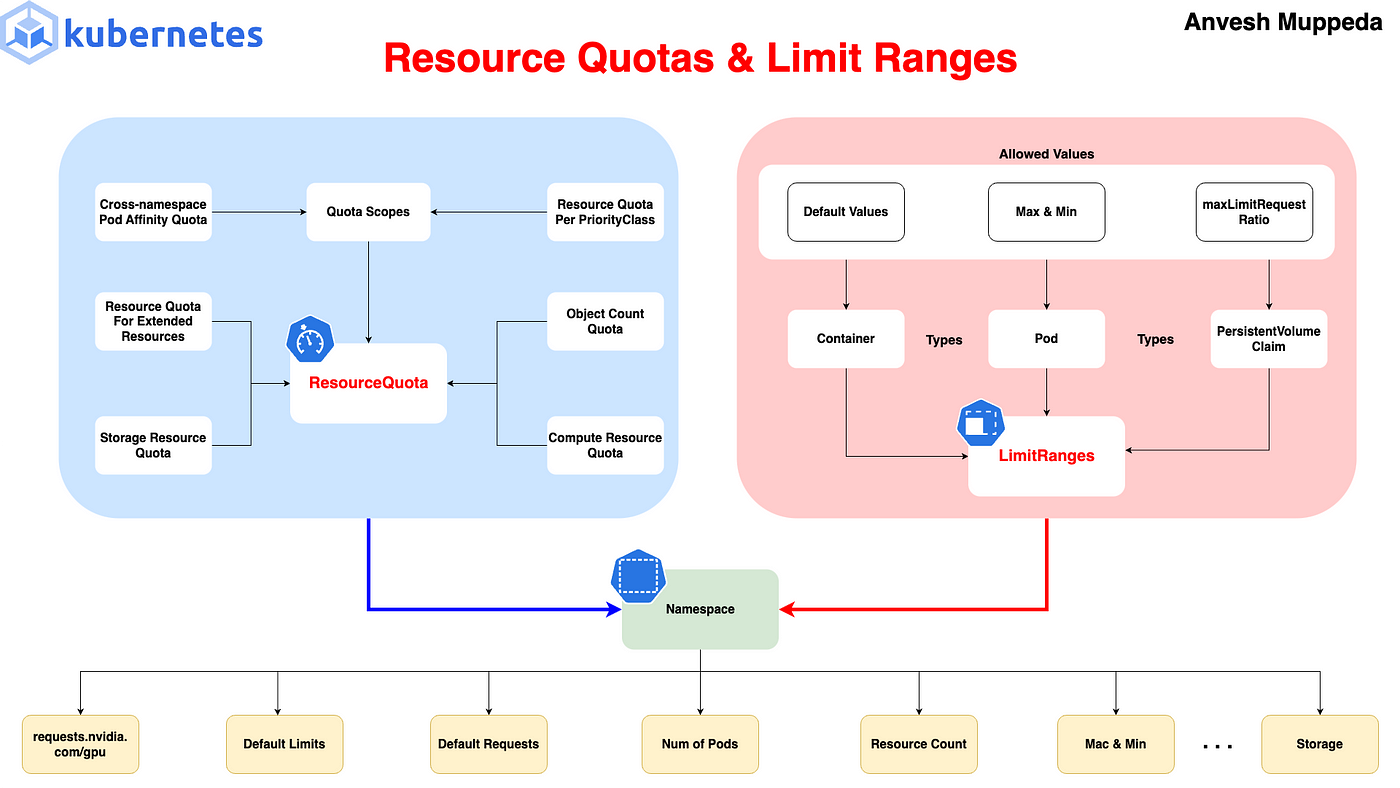
توضیحات: زمانی که یک پاد بیش از حد مجاز namespace منابع را درخواست کند، ممکن است با این وضعیت برخورد کنید.
برخی از علتها و راهحلهای آن:
-
- تنظیمات ضعیف منابع: درخواستهای مربوط به منابع فراتر از خط و مرز تعیین شده مجاز قرار گرفتهاند. راهحل: از kubectl describe quota <quota-name> برای بررسی تخصیصها استفاده کنید و بهینهسازی نمایید.
- پیکربندی نامناسب در سطح namespace: با استفاده کردن بیش از حد منابع کل اجزای موجود در namespace، میتواند از تخصیص منابع به پاد عبور کند. راهحل: بررسی و تنظیم ResourceQuotaها بر اساس نیاز در namespace ایجاد کنید.
۱۱. مشکل Out of Memory:
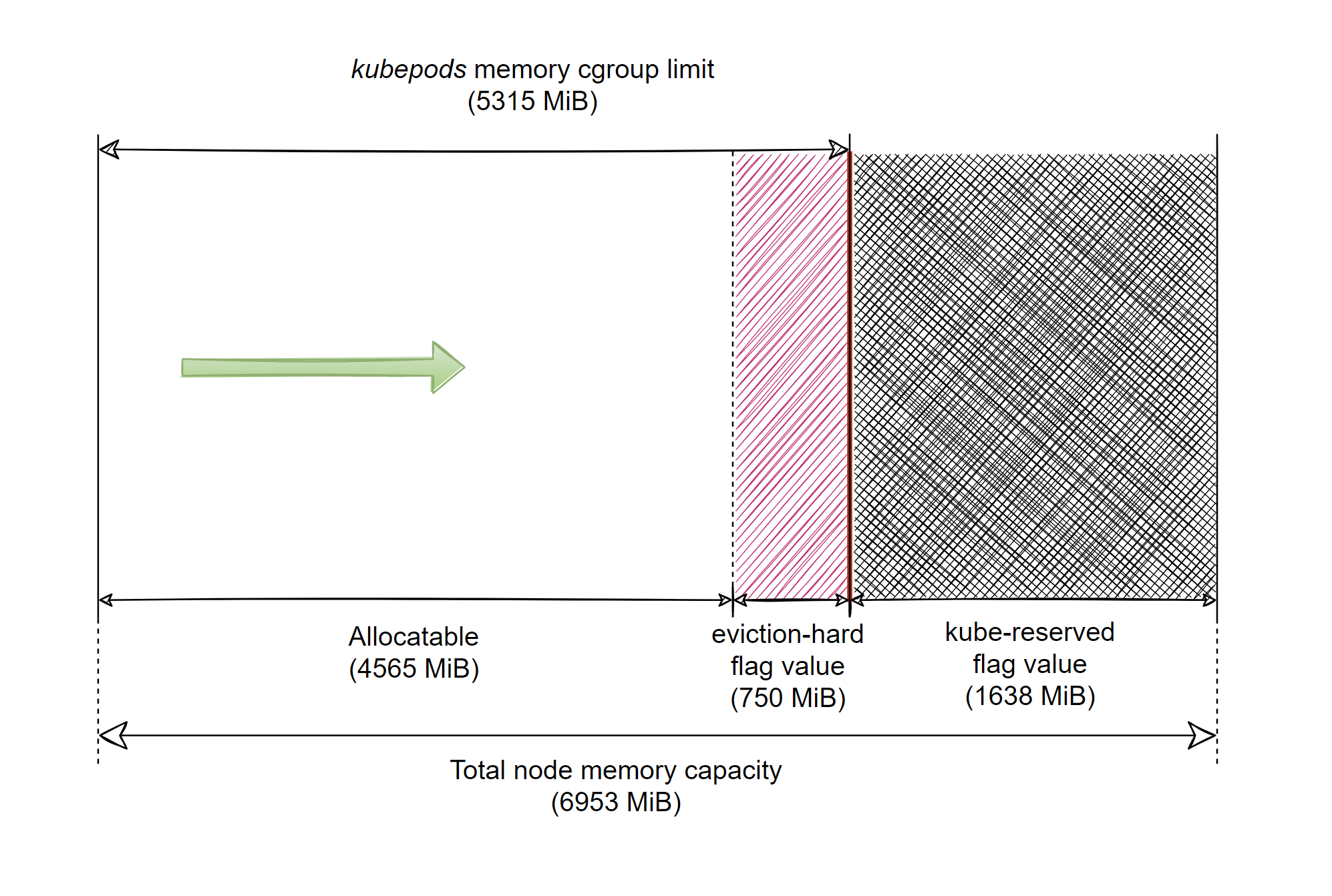
توضیحات: وضعیت OOMKilled زمانی اتفاق میافتد که کوبرنتیز به دلیل مصرف بالای Ram، پاد را متوقف میکند.
برخی از علتها و راهحلهای آن:
-
- اجتناب از پیکربندی نادرست منابع: تخصیص Ram و CPU پایینتر از میزان مصرف تعیین شده میتواند موجب این وضعیت شود. راهحل: مجدد استفاده از kubectl top pods برای بررسی Ram و CPU و بهینهسازی آنها. باید میزان مصرف برای پاد رو ارزیابی کنیم. اینجا VPA میتونه بهمون کمک کنه و پیشنهاد بده که چقدر برای پاد منابع تنظیم کنیم.
- استفاده نامناسب از منابع: پاد در وضعیت بدی قرار گرفته که هر چقدر منابع در اختیارش بدیم مصرف میکنه. راهحل: با بررسی کد دلیل استفاده زیاد منابع رو پیدا و آن را برطرف کنید.
۱۲. مشکل RBAC Forbidden Errors:
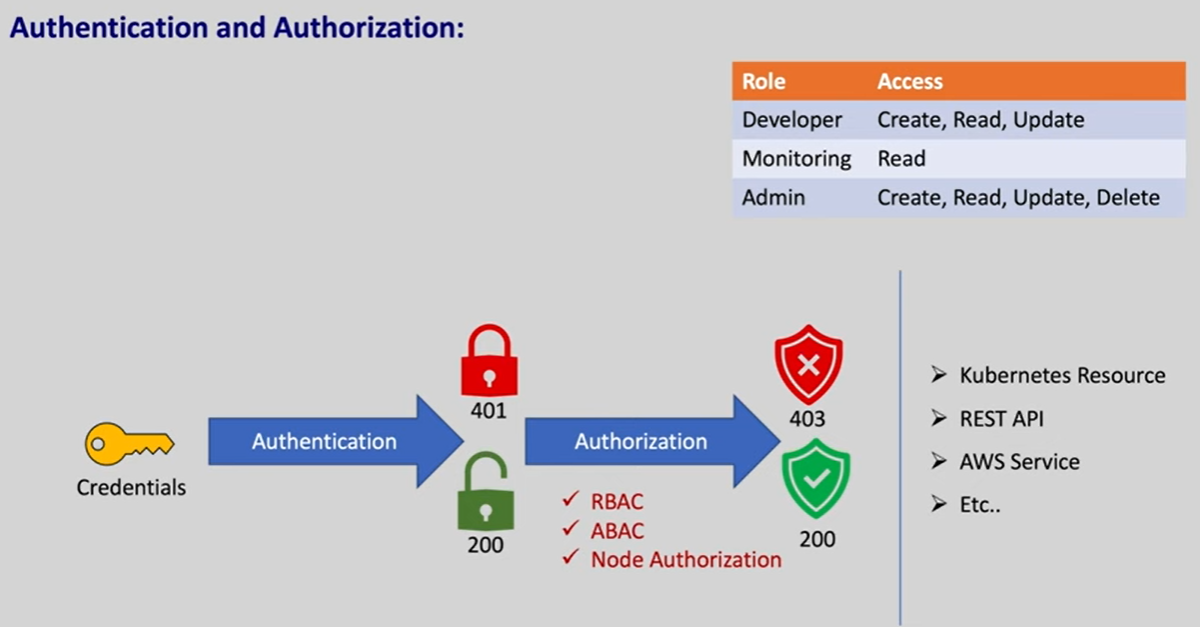
توضیحات: در این زمان، یک کاربر یا سرویس دسترسیهای لازم برای انجام عملیات مورد نظر را ندارد. داریم کاری رو انجام میدیم که دسترسی لازم برای انجام آن را نداریم.
برخی از علتها و راهحلهای آن:
- مجوزهای نامناسب: تعریف نادرست نقشها و سیاستهای دسترسی عامل این وضعیت است. راهحل: با kubectl get roles و kubectl describe roles <role-name> مجوزها و سیاستها را بازنگری کنید.
- تقسیم دسترسیهای اداره: تعریف نادرست دسترسی کاربران در نقشها میتواند به خطای Forbidden منجر شود. راهحل: تنظیم مجدد نقشها را در رابطه با نیازمندیهای دسترسی انجام دهید. بیشتر وقت این مشکل زمانی که با ادمین ارتباط بگیریم میتواند حل شود.
۱۳. مشکل CoreDNS Not Resolving Services:
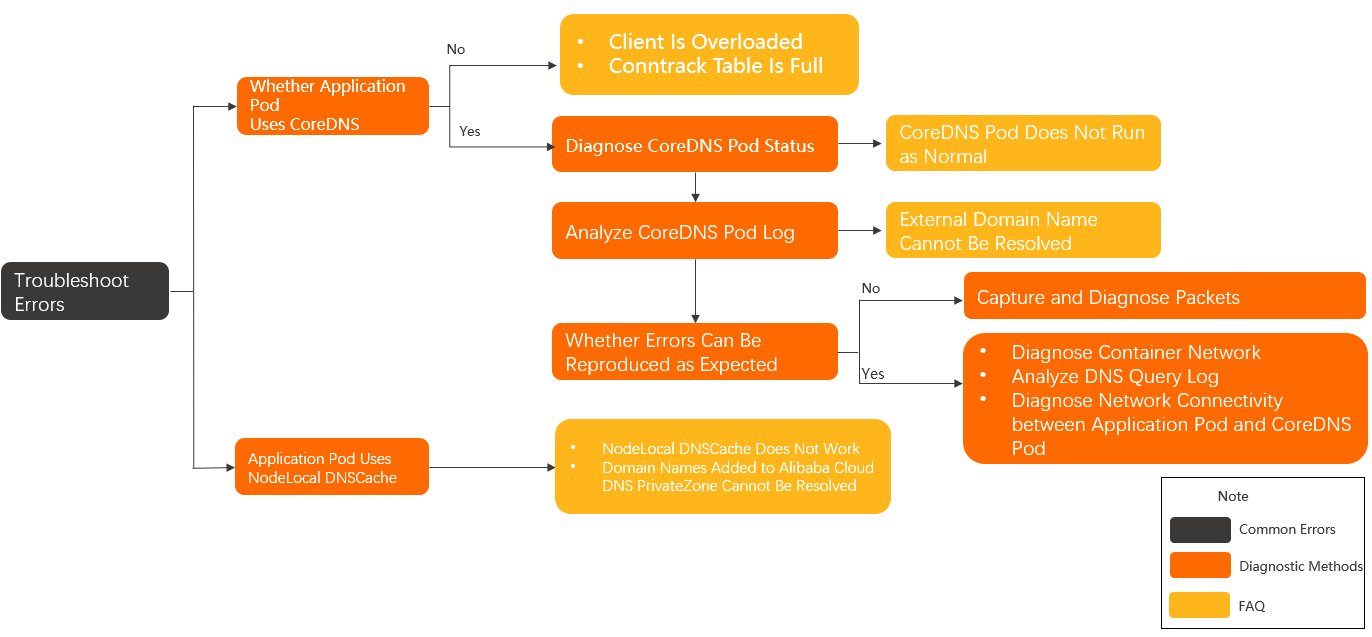
توضیحات: حتی زمانهایی که تغییرات در سرویسهای جدید در حال اعمال است، CoreDNS ممکن است نتواند این تغییرات را شناسایی کند در نتیجه آدرسها درست resolve نمیکند و فرآیند service discovery با مشکل مواجه میشود.
برخی از علتها و راهحلهای آن:
- پیکربندی CoreDNS نادرست: اگر پیکربندی CoreDNS به درستی تنظیم نشده باشد، ممکن است به این وضعیت منجر شود. راهحل: از kubectl -n kube-system describe configmap coredns برای بررسی پیکربندی استفاده کنید.
- پادهای مربوط به CoreDNS: احتمال دارد یکی از پادهای مربوط به CoreDNS دچار مشکل شده باشد. راهحل: از kubectl logs برای بررسی لاگهای CoreDNS استفاده کنید.
- لود زیاد سرویس CoreDNS: احتمال دارد در لود زیاد سرویس CoreDNS دچار اختلال شود. راهحل: میتوانید تعداد پادها یا میزان منابع سرویس CoreDNS رو افزایش دهید.
۱۴. مشکل NodePort Not Accessible:
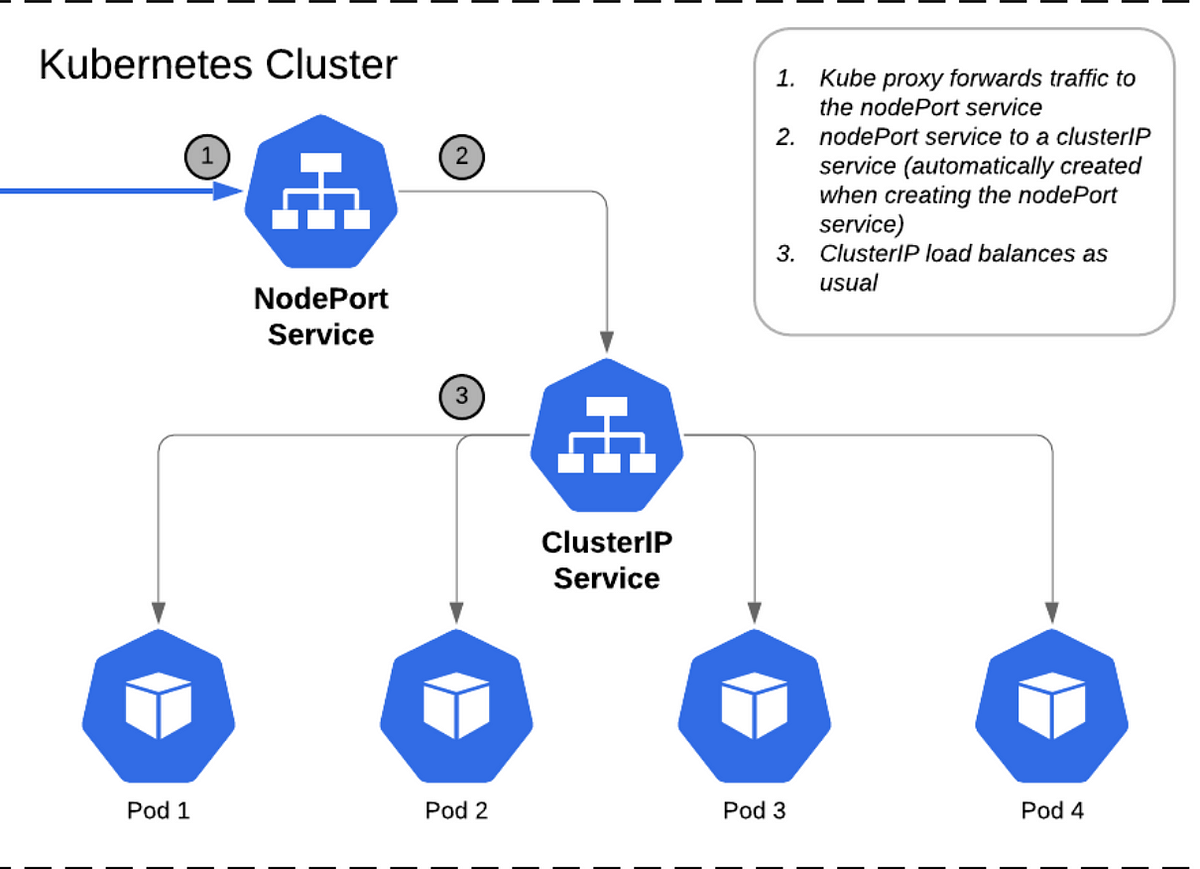
توضیحات: مشکلات در عدم دسترسی به سرویسهای NodePort که ممکن است ناشی از تنظیمات نادرست سیاستهای شبکه یا firewall یا درست کار نکردن kube-proxy باشد.
برخی از علتها و راهحلهای آن:
-
- پیکربندی نادرست: که ممکن است پیکربندی نادرست NodePort منجر به عدم دسترسی شود. راهحل: از kubectl describe service service-name برای بررسی تنظیمات استفاده کنید.
- Firewall: ممکن است دیواره فایروال در سطح نودها مانع از دسترسی به پورتهای NodePort شود. راهحل: از تنظیمات firewall برای بازگشایی پورتهای ضروری استفاده کنید.
- عدم عملکرد درست kube-proxy: ممکن است kube-proxy داره درست کار نمیکنه. راهحل: اینجا باید لاگ kube-proxy رو بررسی کنیم و مشکل رو پیدا کنیم.
- تعداد زیاده سرویسها: وقتی تعداد سرویسها زیاد باشه مثلا ۱۰۰۰ تا یا بیشتر kube-proxy با مد iptables ممکنه درست عمل نکنه. راهحل: اینجا باید از مدهای دیگه kube-proxy مثلا ipvs استفاده کنیم.
۱۵. مشکل Readiness/Liveness Probe Failing:
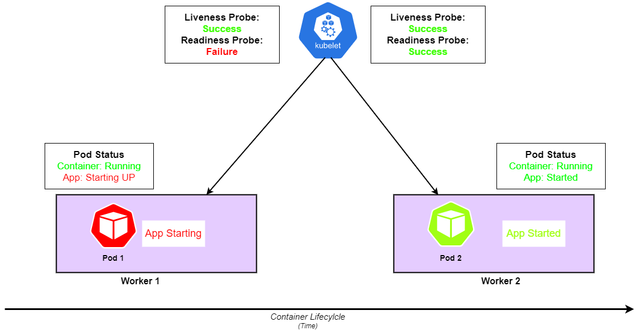
توضیحات: چکهای Readiness به پادها اجازه میدهد تا قبل از قابل دسترسی بودن درخواستها به طور صحیح آماده شوند. چکهای Liveness بررسی میکند که آیا پاد در حال اجرا است یا خیر. در صورتی که این چکها شکست بخورند، کوبرنتیز پاد را متوقف کرده یا دوباره راهاندازی میکند.
برخی از علتها و راهحلهای آن:
-
- پیکربندی نامناسب: تنظیم زمانهای ناکافی برای چکهای Liveness و Readiness. راهحل: زمانهای handshake را در پاد خود تغییر دهید و مطمئن شوید که به میزان نیاز هستند.
- مشکلات در برنامه: ممکن است وضعیت پاد به دلیل بروز خطاها در کد به ناکارآمدی دچار شود و خطا بخورد. راهحل: لاگها را با kubectl logs pod-name بررسی کرده و کد را اشکالزدایی کنید.
۱۶. مشکل Pod Stuck in Terminating:
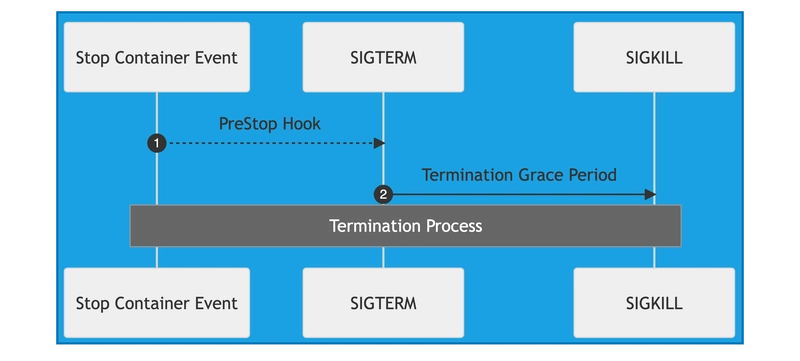
توضیحات: وقتی پاد به دلیل مسائلی مانند وجود وابستگیها یا مشکلات در حذف دادهها در وضعیت Terminating باقی میماند، این وضعیت رخ میدهد. میخوای پاک بشه ولی نمیشه.
برخی از علتها و راهحلهای آن:
-
- مشکلات حذف: اگر پاد در حال حاضر به یک منبع دیگر وابسته باشد، نمیتواند بهسرعت حذف شود. راهحل: از kubectl delete pod <pod-name> –grace-period=0 –force برای حذف اجباری پاد استفاده کنید.
- استفاده از Finalizers: ممکن است Finalizers مانع از حذف پاد شوند. راهحل: بررسی کنید که آیا Finalizerها بر روی پاد فعال هستند و در صورت نیاز آنها را حذف کنید.
- هنوز پروسههای داخل پاد تمام نشده: ممکن است پاد شما در حال کار باشد و فرآیند kill شدن آرامی را طی میکند. راهحل: با force کردن میتونید syskill آن را تغییر بدید و سریع خاموشش کنید اما توصیه نمیشه. بهتره فرآیندی که برای پاد تنظیم شده درست طی شود.
۱۷. مشکل Networking Issues:
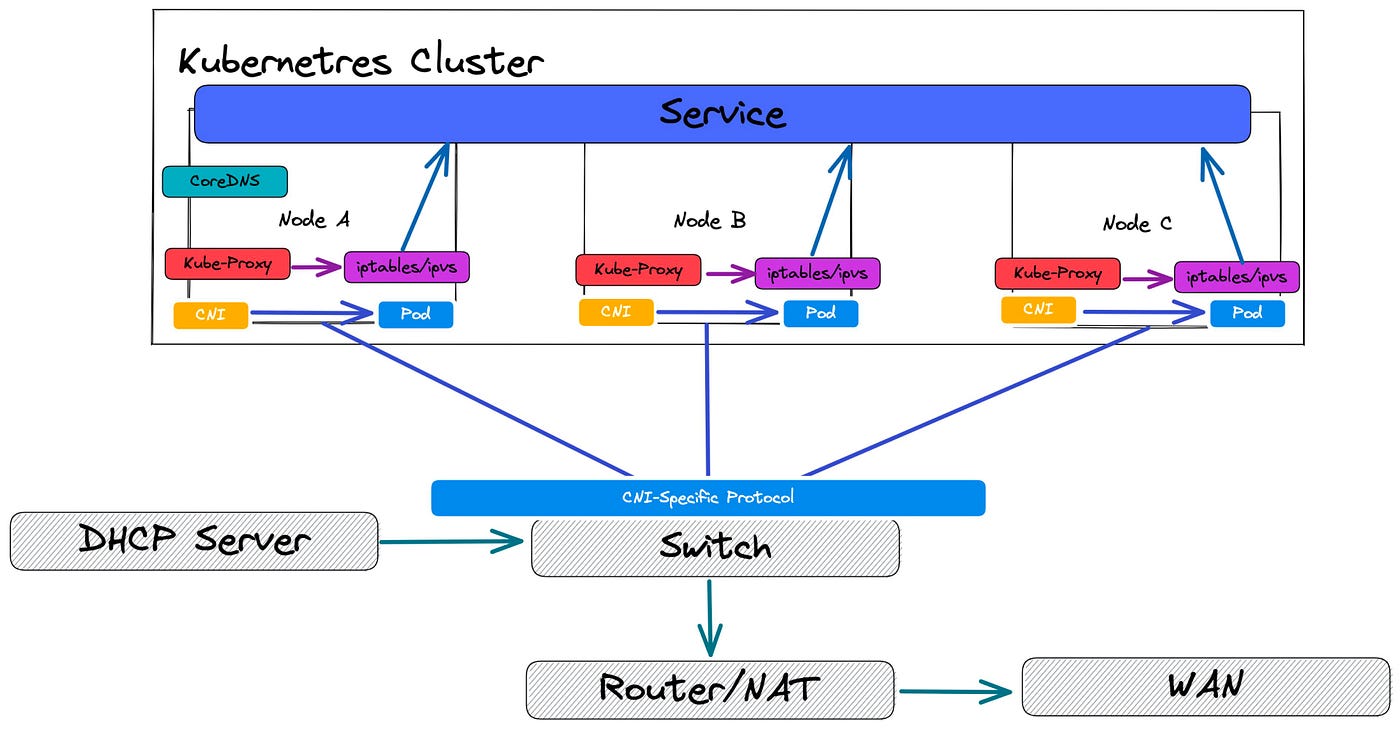
توضیحات: مشکلات شبکهای در کوبرنتیز میتوانند به سرعت بر عملکرد و قابلیتهای کلاستر تأثیر بگذارند. با شناسایی علل مشکلات و اجرای راهحلهای مشخص، میتوانید از بروز این مشکلات جلوگیری کرده و شبکهی کلاستر خود را بهینه کنید. به یاد داشته باشید که نظارت مداوم بر وضعیت شبکه و کاربران همچنین میتواند به افزایش امنیت و عملکرد کلاستر کمک کند. در ضمن این مشکلات میتواند خیلی گسترده و بزرگ باشد ولی در ادامه به برخی از آنها اشاره میکنم.
برخی از علتها و راهحلهای آن:
-
- مشکلات مربوط به CNI: پیکربندی نادرست CNI یا مشکل در نصب آن. راهحل: از مستندات CNI که استفاده میکنید برای راهاندازی و پیکربندی صحیح استفاده کنید. بررسی کنید که سرویسهای CNI در حال اجرا هستند: kubectl get pods -n kube-system
- Overlapping IP Address Space: ممکن است دو شبکه با یک آدرس IP مشابه در کلاستر وجود داشته باشد که باعث اختلال در مسیرهای شبکه میشود. راهحل: اطمینان حاصل کنید که آدرس IP خاصی که برای هر کانتینر استفاده میشود، یکتا باشد و با دیگر شبکهها تداخل نداشته باشد.
- مشکلات مربوط به Ingress: ممکن است Ingress به درستی پیکربندی نشده باشد و مسیرهای ترافیک به درستی مشخص نشده باشند. راهحل: وضعیت و پیکربندی Ingress را بازبینی کنید با استفاده از دستور kubectl describe ingress ingress-name. اطمینان حاصل کنید که پادهای ingress به درستی اجرا میشوند.
- Network Latency: ممکن است مشکلات در بین زیرساخت شبکه یا بار زیادی وجود داشته باشد که منجر به تأخیر در ارتباطات شود. راهحل: استفاده از ابزارهایی مانند Ping و Traceroute برای شناسایی تأخیرها و مشکلات ممکن. باید از وضعیت شبکهی نود مطلع بشید و بررسی کنید که چرا داره این اتفاق میافته.
۱۸. Ingress Not Routing Traffic:
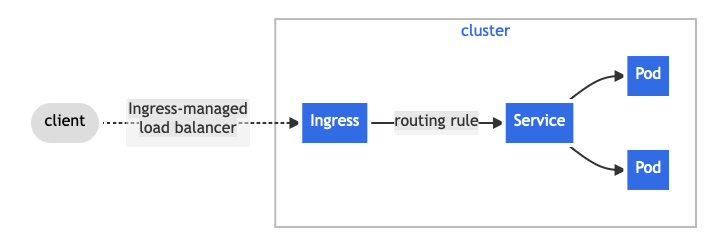
توضیحات: این خطا نشاندهنده این است که Ingress نتوانسته است به درستی ترافیک ورودی را به پادهای مرتبط هدایت کند.
برخی از علتها و راهحلهای آن:
- پیکربندی اشتباه Ingress: وقتی پیکربندی های Ingress به درستی انجام نشده باشد، این وضعیت بروز میکند. راهحل: از دستور kubectl describe ingress ingress-name برای شناسایی مشکلات پیکربندی استفاده کنید.
- سرورهای پشتیبان غیر فعال: ممکن است پادهای پشتیبان به صورت موقتی غیرفعال باشند. راهحل: اطمینان حاصل کنید که همه پادهای پشتیبان برای سرویسهای مرتبط در حال اجرا هستند.
۱۹. مشکل Persistent Storage Issues:
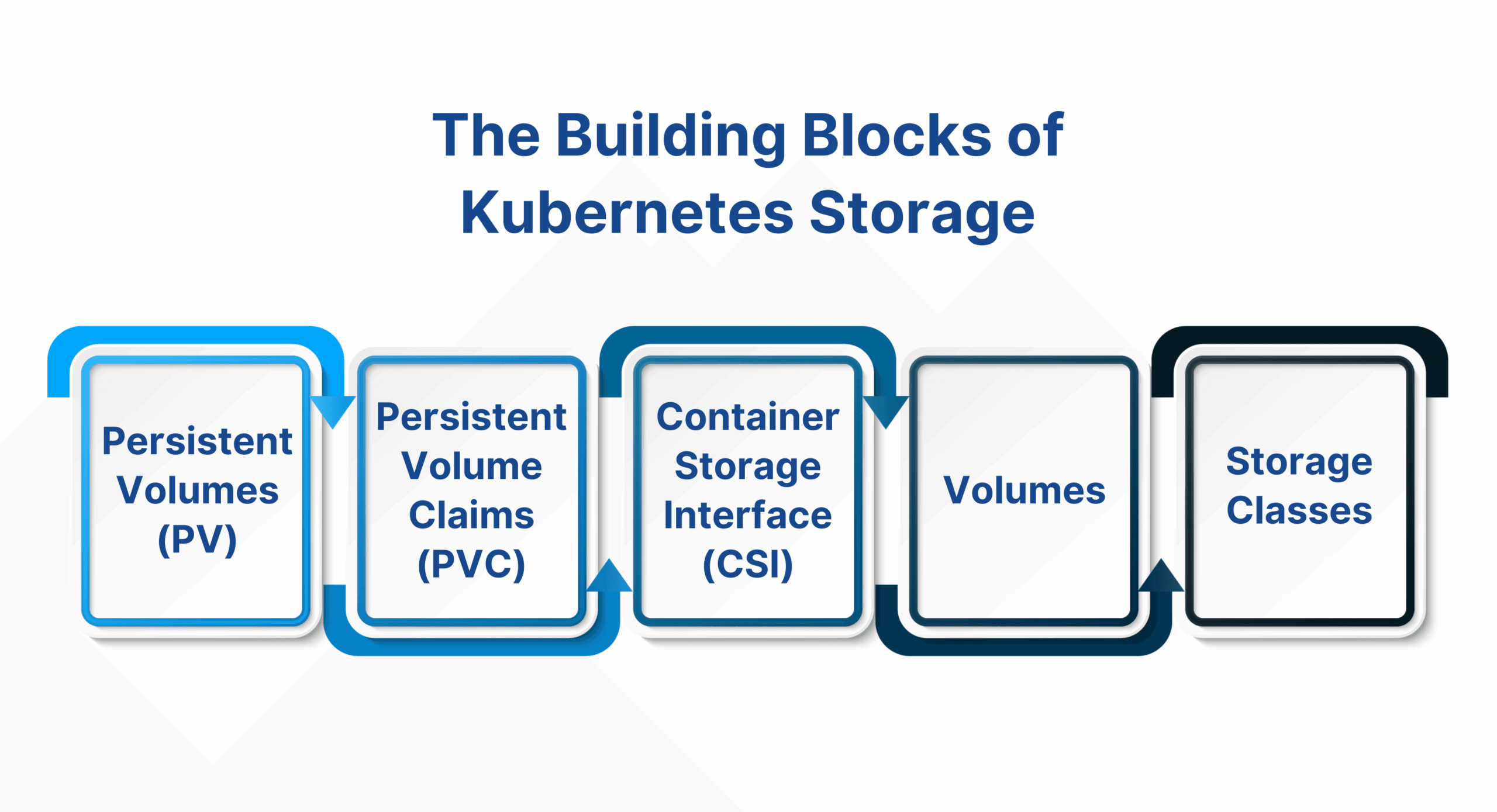
توضیحات: مشکلات مربوط به ذخیرهسازی پایدار زمانی رخ میدهند که پادها نتوانند به درست به دادهها دسترسی یابند.
برخی از علتها و راهحلهای آن:
- پیکربندی PVC نادرست: اگر PVCها به درستی پیکربندی نشده باشند یا فضایی برای ذخیره فراهم نکنند، پادها نمیتوانند به دادهها دسترسی یابند. راهحل: از kubectl describe pvc pvc-name استفاده کنید تا وضعیت PVCها را بررسی کرده و مشکلات را شناسایی کنید.
- عدم دسترسی به Persistent Volume: مشکلات در اتصال بین PVC و Persistent Volume میتواند منجر به دسترسی ناپایدار شود. راهحل: از kubectl get pv برای بررسی وضعیت Volumeها استفاده کنید و اطمینان حاصل کنید که در دسترس هستند.
نتیجهگیری:
مدیریت و راهبری کلاستر کوبرنتیز بدون شکستها و چالشها و اینجور خطاها غیرممکن است. در این مقاله به بررسی مشکلات رایج همانند CrashLoopBackOff ، ImagePullBackOff ، Network Issues و سایر خطاهای متداول پرداختیم. هر یک از این مشکلات میتواند بر کارایی و عملکرد کلی کلاستر تأثیر بگذارد، اما با درک عمیق از علل آنها و انتخاب راهحلهای مناسب، میتوان به طور مؤثر آنها را برطرف کرد.
داشتن observability کامل و پویا، راهکاری مؤثر برای بهینهسازی عملکرد و کاهش خطاها میباشد. با استفاده از مانیتورینگ و لاگینگ مناسب، شما نه تنها میتوانید از بروز این مشکلات جلوگیری کنید بلکه نودهای خود را بهبود بخشد. باید به یاد داشته باشید که مدیریت کلاستر کوبرنتیز یک فرآیند پویا و مداوم است. به روز بودن با ویژگیها و ابزارهای جدید، آموزش تیمهای فناوری و پیادهسازی سیاستهای مناسب خواهند بود تا در برابر تهدیدات و مشکلات ایستادگی کنید. به همین دلیل، با پذیرش این چالشها و آمادهسازی مناسب میتوانید از تمام قابلیتهای کوبرنتیز بهره برده و امنیت، مقیاسپذیری و کارایی سیستمهای خود را به حداکثر برسانید.
بدین ترتیب، با تسلط بر این مشکلات و راهحلها، میتوانید تجربهای مثبت و بهینه را در مدیریت کلاسترهای کوبرنتیز خود به دست آورید. اگر به اطلاعات بیشتری نیاز دارید یا سؤالی دارید، حتما بپرسید تا پیرامونش بیشتر و کاملتر توضیح بدم.




