توی این قسمت میریم به سراغ اینکه بررسی کنیم چطوری میتونیم ریسورسهای خودمون رو به صورت کاستوم شده توی کوبرنتیز تعریف کنیم و بعدش هم در مورد اُپراتورها توی کوبرنتیز توضیح میدیم.
خب یه مروری کنیم پستهای قبلی رو:
- دواپس چیه و چرا لازمه؟ اینجا در مورد دواپس و ضرورت استفاده از آن صحبت کردم.
- مسیر شغلی دواپس اینجا در مورد مسیر شغلی دواپس و موارد پیرامون آن صحبت کردم.
- چطور اپلیکیشن مناسب کلاد آماده کنیم؟ و اینجا توضیح دادم که چطور میتونیم یه اپلیکیشن مناسب کلاد توسعه بدیم.
- چه عمقی از لینوکس برای دواپس لازمه؟ و اینجا توضیح دادم که کدوم موارد لینوکس برای دواپس الزامی هست که اول سراغ اون موارد بریم.
- خودکارش کن، مشکلاتت حل میشه 🙂 در اینجا در مورد اتومیشن و اینکه انسیبل چیه و چه کمکی به ما میکنه صحبت کردم.
- در مسیر دواپس اینبار اجزای اصلی انسیبل تو این پست اجزای انسیبل رو معرفی کردم و آنها را شرح دادم.
- در مسیر دواپس به داکر رسیدم. (قسمت اول) تو این پست داکر رو شروع کردیم و اونو معرفی کردیم.
- در مسیر دواپس اینبار: پشت داکر چه خبره؟ (قسمت دوم) توی این پست در مورد تکنولوژی هایی که داکر ازشون استفاده میکنه توضیح دادیم.
- در مسیر دواپس اینبار: والیوم و نتورک داکر (قسمت سوم) توی این پست در مورد شبکه توی داکر و اینکه چطوری دیتای کانتینر رو میتونیم نگه داریم توضیح دادیم.
- در مسیر دواپس اینبار: داکر فایل ( قسمت چهارم ) توی این پست در مورد اینکه چطور با استفاده از داکر اپلیکیشن مون رو بیلد کنیم و ایمیج بسازیم توضیح دادیم.
- در مسیر دواپس اینبار: کامپوز فایل و داکر کامپوز (قسمت پنجم) توی این پست در مورد اینکه چطور روند دیپلوی کردن سرویسهامون و کانفیگ اونها رو به صورت کد داشته باشیم توضیح دادیم.
- در مسیر دواپس: اینبار داکر سوآرم (قسمت ششم) توی این پست در مورد داکر سوآرم و اینکه چطوری به کمک داکر چنتا سرور رو کلاستر کنیم، توضیح دادیم.
- در مسیر دواپس اینبار: دور و بری های داکر (قسمت هفتم) توی این پست در مورد ابزارهای جانبی که بهمون توی کار با داکر کمک میکنن توضیح دادیم.
- در مسیر دواپس: جمع بندی داکر (قسمت هشتم) توی این پست در مورد امنیت داکر توضیح دادیم و در آخر هم یه سری از بست پرکتیسها و تجربیات خودم رو گفتم.
- تست نوشتن و شروع مسیر CI/CD (قسمت اول) توی این پست انواع تست رو بررسی کردیم و با ابزارهای CI/CD آشنا شدیم و یه مقایسه بین گیتلب و جنکینز داشتیم.
- در مسیر CI/CD گیت رو بررسی میکنیم (قسمت دوم) توی این پست قبل ورود به گیتلب نیاز بود که گیت و ورژن کنترل سیستم ها رو یه بررسی کنیم.
- در مسیر CI/CD شناخت گیتلب (قسمت سوم) توی این پست اجزای گیتلب رو بررسی کردیم و با کامپوننتهای مختلفی که داره بیشتر آشنا شدیم.
- در مسیر CI/CD پایپلاین و رانر گیتلب (قسمت چهارم) توی این پست پایپلاین و رانر گیتلب رو بررسی کردیم.
- در مسیر CI/CD وریبل، گیتآپس و جمعبندی (قسمت پنجم) توی این پست وریبلهای گیتلب رو بررسی کردیم و یه معرفی کوتاه از گیتآپس و آتودواپس کردیم و در انتها یه مقدار تجربههای خودم رو در گیتلب باهاتون به اشتراک گذاشتم.
- مسیر Observability (قسمت اول) توی این پست معرفی observability رو داشتیم و مقایسه اش با مانیتورینگ و یه توضیح مختصر هم در مورد اپنتلهمتری دادیم.
- در مسیر Observability، الک (قسمت دوم) توی این پست استک قدرتمند ELK رو بررسی کردیم.
- در مسیر Observability، جمع بندی استک الک (قسمت سوم) توی این پست بقیه کامپوننتهای استک الک رو بررسی کردیم و fluentd و fluentbit رو مقایسه کردیم و نهایتا یه معرفی هم روی opensearch داشتیم.
- در مسیر Observability، استک پرومتئوس (قسمت چهارم) توی این پست یه معرفی اولیه داشتیم روی استک پرومتئوس.
- در مسیر Observability، استک پرومتئوس (قسمت پنجم) توی این پست یه مقدار کامپوننت های استک پرومتئوس رو بیشتر بررسی کردیم.
- در مسیر Observability، استک ویکتوریا (قسمت ششم) توی این پست استک ویکتوریا رو معرفی کردیم و سعی کردیم با پرومتئوس مقایسهاش کنیم.
- در مسیر Observability، میمیر (قسمت هفتم) توی این پست در مورد ابزار میمیر از ابزارهای گرافانا توضیح دادیم و کاربردش رو بررسی کردیم.
- در مسیر Observability، لوکی (قسمت هشتم) توی این پست در مورد ابزار گرافانا برای مدیریت لاگ یعنی لوکی توضیح دادیم و آخرشم یه معرفی کوتاه رو graylog داشتیم.
- در مسیر Observability، تمپو (قسمت نهم) توی این پست در مورد تریسینگ توضیح دادیم و گرافانا تمپو رو بررسی کردیم و یه معرفی کوتاه روی Jaeger داشتیم
- در مسیر Observability، گرافانا (قسمت دهم) توی این پست در مورد گرافانا و HA کردنش و همچنین یه سری از ابزارهاش مثل alloy , incident, on-call توضیح دادیم.
- آغاز مسیر کوبر (قسمت اول) تو این قدم به معرفی ابزارهای ارکستریشن پرداختیم و مدارک کوبرنتیز رو بررسی کردیم.
- کوبر سینگل ( قسمت دوم ) توی این قدم در مورد kubectl , kubeconfig توضیح دادیم و تعدادی ابزار رو معرفی کردیم که به کمک اونها میتونیم یک کوبرنتیز دمهدستی واسه تستهامون داشته باشیم.
- کامپوننتهای کوبر ( قسمت سوم ) توی این پست کامپوننتهای مختلف کوبرنتیز رو بررسی کردیم و اجزای نودهای مستر و ورکر رو دونه دونه بررسی کردیم و توضیح دادیم.
- پادها و مدیریت اونها در کوبرنتیز (قسمت چهارم) توی این پست در مورد پاد توی کوبرنتیز توضیح دادیم و موارد مربوط به اون رو بررسی کردیم.
- ورکلودهای کوبر و مدیریت منابع کوبر (قسمت پنجم) توی این پست در مورد namespaceها توی کوبر توضیح دادیم و انواع ورکلود کوبر رو بررسی کردیم.
- اگه لازم شد کوبر خودش گنده میشه! ( قسمت ششم ) توی این پست در مورد سه نوع ورکلود مرتبط با scaling به صورت خودکار در کوبرنتیز توضیح دادیم.
- نتورک کوبر (قسمت هفتم) توی این قسمت انواع سرویس توی کوبرنتیز رو بررسی کردیم و در مورد مفاهیم اینگرس و نتورک پالیسی توضیح دادیم.
- استورج کوبرنتیز (قسمت هشتم) توی این قسمت در مورد انواع استورج توی کوبرنتیز توضیح دادیم و مفاهیم PV و PVC و Storage Class رو بررسی کردیم.
- پراب، ریکوئست و لیمیت (قسمت نهم) توی این قسمت موارد مربوط به محدود کردن منابع کانتینر توی کوبرنتیز رو بررسی کردیم و در مورد انواع probe ها توی کوبرنتیز توضیح دادیم.
- پاد تو نود (قسمت دهم) توی این قسمت درمورد فرآیند انتقال پاد به نود مناسب مفاهیم پیشرفتهتری مثل affinity و anti-affinity و taint و toleration رو بررسی کردیم.
- اولویت پاد و امنیت (قسمت یازدهم) توی این قسمت در مورد تعیین اولویت برای پادها و جنبههای مختلف امنیت در کوبرنتیز توضیح دادیم.
- کنترل دسترسی به کوبر (قسمت دوازدهم) توی این قسمت در مورد مراحل دسترسی به api کوبرنتیز صحبت کردیم و بعدش مفاهیمی مثل سرویس اکانت رو توضیح دادیم.
- دیزاین کلاستر (قسمت سیزدهم) توی این قسمت در مورد طراحی و دیزاین یک کلاستر و روشهای مختلفی که داره توضیح دادیم و همچنین تفاوت روشهای مختلف تقسیم منابع در کلاسترها را بررسی کردیم.
- مالتی تننسی در کوبر (قسمت چهاردهم) توی این قسمت چالشهای مربوط به داشتن چند مستاجر بر روی کلاستر کوبرنتیز توضیح دادیم.
- هلم (قسمت پانزدهم) توی این قسمت پکیج منیجر معروف کوبرنتیز یعنی Helm رو بررسی کردیم و در موردش ویژگیها و کاربردهاش توضیح دادیم.
توصیه میکنم که حتما این پستها رو هم مطالعه کنید. بریم که ادامه بدیم.

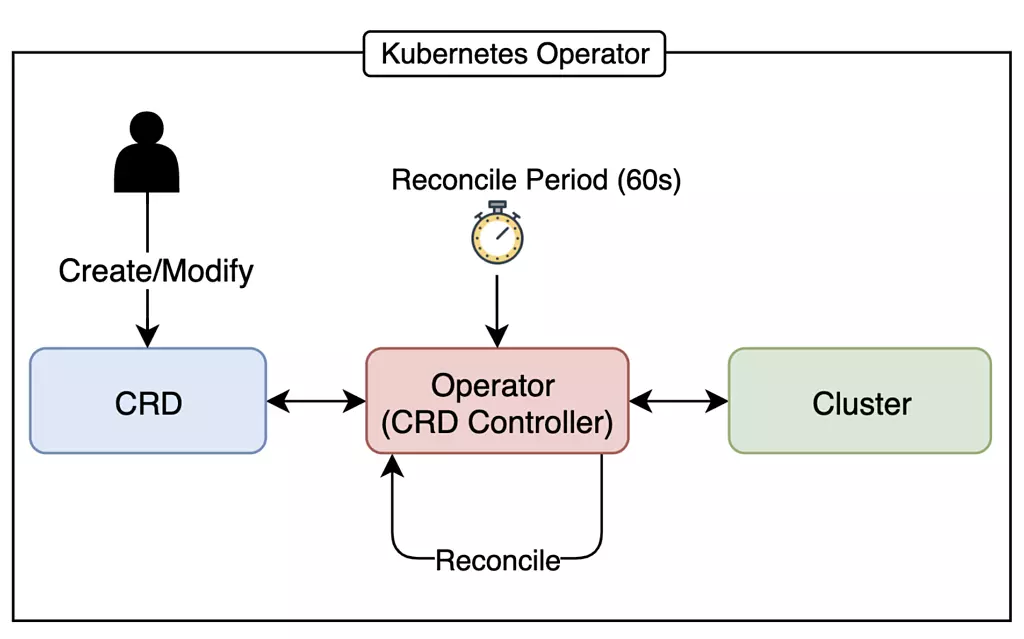
تعریف منابع سفارشی (Custom Resource Definitions – CRDs)
در دنیای کوبرنتیز، انعطافپذیری و قابلیت گسترش از اهمیت بالایی برخوردار است. کوبرنتیز یک API قدرتمند برای مدیریت منابعی مانند Pod، Deployment و Service ارائه میدهد. اما اگر بخواهید منابعی را مدیریت کنید که بهصورت پیشفرض توسط کوبرنتیز پشتیبانی نمیشوند، چه باید کرد؟ اینجاست که CRDs وارد عمل میشوند.
توی کوبرنتیز CRDها به شما این امکان را میدهند که منابع سفارشی خود را تعریف کرده و API کوبرنتیز را مطابق نیازهای خود گسترش دهید. در این مطلب، یک مثال عملی از کار با CRDها را بررسی میکنیم، جایی که یک کنترلر سفارشی ConfigMapها را بر اساس منابع سفارشی مدیریت میکند.
چرا از CRDها استفاده کنیم؟
توی کوبرنتیز CRDها بسیار قدرتمند هستند، زیرا به شما این امکان را میدهند که منابع مربوط به برنامههای خاص خود را به شیوهای بومی (Native) در کوبرنتیز مدیریت کنید. دلایل استفاده از CRDها:
- انتزاع (Abstraction): با استفاده از CRDها میتوانید منطق پیچیده را در منابع سفارشی پنهان کنید و مدیریت برنامهها را سادهتر کنید و از امکانات کوبرنتیز برای مدیریت منابع خود استفاده کنید.
- یکپارچگی (Consistency): تعریف منابع سفارشی به شما کمک میکند تا برنامههای خود را در محیطهای مختلف بهصورت یکپارچه مدیریت کنید.
- خودکارسازی (Automation): CRDها امکان خودکارسازی را فراهم میکنند و به شما اجازه میدهند کنترلرهای سفارشی ایجاد کنید که وضعیت منابع را نظارت و اصلاح کنند.
در ادامه این مبحث نحوه نصب یک منبع سفارشی در API کوبرنتیز از طریق ایجاد CustomResourceDefinition را بررسی میکنیم.
مطالب این پست نیاز به نسخه سرور کوبرنتیز ۱.۱۶ یا بالاتر دارد. برای بررسی نسخه، از دستور زیر استفاده کنید:
kubectl version
ایجاد یک CustomResourceDefinition
وقتی یک CustomResourceDefinition (CRD) جدید ایجاد میکنید، API Server کوبرنتیز یک مسیر RESTful جدید برای هر نسخهای که مشخص میکنید ایجاد میکند. منبع سفارشی ایجاد شده میتواند در محدوده فضای نام (Namespace) یا سراسری (Cluster-scoped) باشد. حذف فضای نام، تمام آبجکتهای CRD داخل آن را نیز حذف میکند. اما خود CRDها غیرمحدودهای (Non-namespaced) هستند.
مثال:
فایل زیر را در resourcedefinition.yaml ذخیره کنید: