مقدمه
خب، همهی ما میدونیم که کوبرنتیز چقدر میتونه شگفتانگیز باشه! این پلتفرم مدیریت کانتینر، بهطور واقعاً قدرتمند و مقیاسپذیر طراحی شده تا به ما کمک کنه اپلیکیشنهامون رو به راحتی اجرا کنیم. اما گاهی وقتها اوضاع بر وفق مراد پیش نمیره و با چالشهایی روبرو میشیم که میتونه کار ما رو مختل کنه.
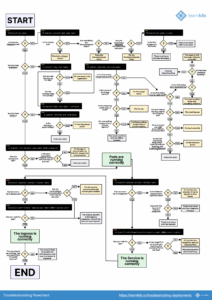
در این مطلب، میخواهیم نگاهی به مشکلات رایجی که ممکنه توی کلاستر کوبرنتیز باهاشون مواجه بشید بندازیم. از خطاهای آزاردهنده مثل CrashLoopBackOff و ImagePullBackOff گرفته تا مشکلاتی پیچیدهتر مثل RBAC Forbidden Errors و Service Unavailable (503) ، ما همگی اینها رو بررسی میکنیم. نمیخواهیم فقط بگیم مشکل از کِی پیش اومده، بلکه به شما میگیم چطوری میتونید این مشکلات رو حل کنید تا اوضاع دوباره به حالت عادی برگرده.
پس خودتونو آماده کنید! بیاید با هم به دنیای مشکلات کوبرنتیز سفر کنیم و راهکارهای مفیدی پیدا کنیم. البته اینا مشکلات رایج و عمومی هست که باهاش مواجه میشیم و مشکلات کوبرنتیز تعدادشون میتونه خیلی بیشتر باشه.
۱. مشکل CrashLoopBackOff:
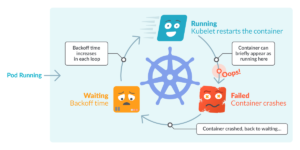
توضیحات: زمانی که یک پاد به طور مداوم در تلاش برای راهاندازی مجدد است و به دلایلی مانند اشکالات داخل کد، تنظیمات نادرست یا عدم توانایی در وابستگیها به وضعیت CrashLoopBackOff میرسد. وقتی که این وضعیت رخ میدهد، کوبرنتیز به منظور جلوگیری از بارگذاری بینهایت، تلاشهای پی در پی برای راهاندازی مجدد پاد را با مکثهای افزایشی انجام میدهد. به همین دلیل نام آن BackOff است. این خیلی خوبه اگر همینطوری ریست کنه خیلی لود روی کلاستر ما اضافه میکنه. با این کار فواصل بین تلاشها تو یه پترنی زیاد میشه و به این صورت لود روی کلاستر رو مدیریت میکند.
برخی از علتها و راهحلهای آن:
-
- خطای کد: ناهماهنگی در کد که منجر به خروج غیرعادی (non-zero exit status) میشود. راهحل: از kubectl logs pod-name برای بررسی لاگهای خطا استفاده کنید تا علت واقعی بروز مشکل را شناسایی کنید. همچنین میتوانید کد را تغییر داده و به صورت محلی آن را اجرا کنید.
- عدم وجود وابستگی: یک پاد ممکن است به منابع یا پادهای دیگر وابسته باشد که در حالت Running نیستند. راهحل: بررسی کنید که آیا تمام وابستگیهای پاد موجود و در حال اجرا هستند یا خیر.
- تنظیمات نادرست: ممکن است متغیرهای محیطی به درستی تعریف نشده باشند یا پیکربندی نادرستی انجام شده باشد. راهحل: اطمینان حاصل کنید که تمامی متغیرهای محیطی، ConfigMaps و Secretها به درستی پیکربندی شدهاند.
۲. مشکل ImagePullBackOff:
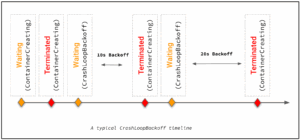
توضیحات: این خطا به این معناست که کوبرنتیز در تلاش است تا یک تصویر کانتینر را دریافت کند، اما برای این کار موفق نیست. در حقیقت، کوبرنتیز چندین تلاش برای دریافت تصویر انجام میدهد و در صورت عدم موفقیت به حالت BackOff (مکث) میرود. دقیقا همانند حالت قبلی که در صورت عدم موفقیت بازهی زمانی بین هر بار تلاش رو بیشتر میکنه که تو لوپ اشتباه نباشه و لود اضافی ایجاد نکند.
برخی از علتها و راهحلهای آن:
- تصویر وجود ندارد یا حذف شده است: تصویر ممکن است در رجیستریای که به آن اشاره شده است، وجود نداشته باشد. راهحل: اطمینان حاصل کنید که نام تصویر و تگ به درستی قید شده باشد. با مراجعه به رجیستری، بررسی کنید که تصویر موجود است.
- مجوز دسترسی: عدم دسترسی به رجیستری (به خصوص هنگام استفاده از رجیستریهای خصوصی). راهحل: از kubectl create secret docker-registry برای ایجاد Secret مورد نیاز برای احراز هویت با رجیستری استفاده کنید.
- معضلات شبکه: ممکن است مشکلات شبکه مانع از اتصال به رجیستری یا دریافت تصویر شوند. راهحل: شبکه خود را بررسی کنید و مطمئن شوید که سرورها به اینترنت یا رجیستری خصوصی دسترسی دارند. معمولا تو ایران این مدل مشکل خیلی زیاد پیش میآید.
۳. مشکل ErrImagePull:
توضیحات: این وضعیت به این معناست که کوبرنتیز نمیتواند به علت خاصی تصویر کانتینر را دریافت کند. این وضعیت معمولاً پیش از حالت ImagePullBackOff اتفاق میافتد و به این معناست که کوبرنتیز تلاش خود را برای دریافت ایمیج آغاز کرده ولی با خطا مواجه شده است. علتها و راهحلهایی که پیشنهاد میشه دقیقا شبیه مشکل دوم هست و دیگه تکرار نمیکنم.
۴. مشکل Evicted:
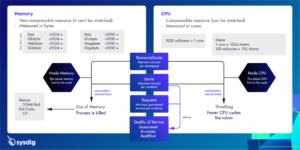
توضیحات: یک پاد به دلیل مصرف بیش از حد منابع (CPU، RAM یا دیسک) از نود خارج شده است. این خروج به منظور جلوگیری از کمبود منابع در نود صورت میگیرد. این فرآیند رو خود کوبرنتیز معمولا برای جلوگیری از دسترس خارج نشدن نود انجام میدهد. در صورتی که مانیتورینگ خوبی داشته باشیم میتونیم از بروز این مشکل جلوگیری کنیم.
برخی از علتها و راهحلهای آن:
- استفاده نادرست از منابع: تنظیمات نادرست در requests و limits منابع میتواند باعث پذیرش بیش از حد منابع شود. راهحل: از kubectl describe pod pod-name استفاده کنید تا وضعیت منابع مصرفی را بررسی کنید.
- کمبود Ram در نود: اگر نود بر اثر کمبود Ram فریز شود، پادهای با بیشترین میزان مصرف حذف میشوند. یه جورایی هر زمانی که توی نود منابع کم بیاد کوبر پادها رو فدا میکنه تا نود رو حفظ کنه. راهحل: نظارت بر میزان مصرف Ram با ابزارهایی مانند kubectl top nodes.
- استفاده از Disk Pressure: گاهی دیسک دچار فشار زیاد میشود و موجب خروج پادها میشود. راهحل: از df -h برای بررسی فضای دیسک استفاده کنید و در صورت نیاز فایلهای غیرضروری را حذف کنید.
۵. مشکل Pending:
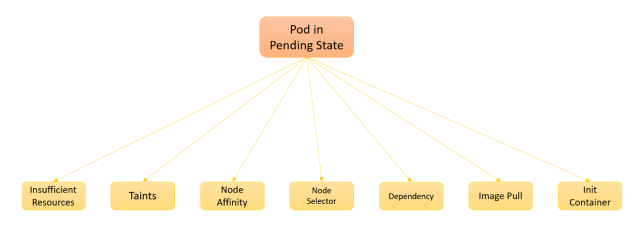
توضیحات: وضعیت Pending نشاندهنده عدم توانایی پاد در راهاندازی است. این وضعیت نشان میدهد که منابع کافی برای تأمین درخواست پاد وجود ندارد. کلا میتونیم این طوری بگیم که تو فرآیند ایجاد پاد شرایط لازم و کافی وجود نداشته. از پایین بودن اسکجولر تا نبود PVC و هر چیزی دیگه میتونه باشه.
برخی از علتها و راهحلهای آن:
-
- محل وجود پاد: ممکن است هیچ نودی در دسترس نباشد که بتواند منابع مورد نیاز پاد را تأمین کند. راهحل: با kubectl get nodes وضعیت نودها را بررسی کنید و در صورت نبود نود خالی، نودهای جدید اضافه کنید یا شرایط لازم برای استقرار پاد رو فراهم کنید.
- عدم تخصیص منابع: نودها به دلیل منابع ناکافی، نمیتوانند پاد را ایجاد کنند. راهحل: منابع هر پاد را در kubectl describe pod pod-name بررسی کنید و در صورت نیاز تخصیص منابع را تغییر دهید.
- سیاستهای زمانبندی (اسکجولینگ): گاهی سیاستهای زمانبندی ممکن است باعث شوند که انتخاب نود مناسب برای پادها دچار مشکل شود. راهحل: سیاستهای زمانبندی را بهینهسازی کنید تا اطمینان حاصل شود که انتخاب نودها به درستی انجام میگیرد.
- عدم دسترسی به کامپوننت زمانبندی (اسکجولینگ): در صورتی که کامپوننت زمانبندی در دسترس نباشد پاد در این وضعیت قرار میگیرد. راهحل: از صحت عملکرد کامپوننت زمانبندی اطمینان حاصل کنید.
۶. مشکل Failed:

توضیحات: وضعیت Failed زمانی رخ میدهد که پاد نتواند به کارکرد عادی خود ادامه دهد و به دلایل مختلفی با خطا مواجه شده یا به طور کامل از بین میرود. دلایل زیادی میتونه داشته باشه و مشکل خیلی عمومی میتونه باشه که به هر دلیلی میتونه به وجود بیاد.
برخی از علتها و راهحلهای آن:
- بررسی عدم قابلیت: ممکن است خطاهای موجود در کد یا پیکربندی نامناسب باعث خروج غیر صحیح پاد شده باشد. راهحل: کد پاد و پیکربندی آن را در محیط محلی یا محیط تستی بررسی کنید.
- نقص در منابع: عدم توانایی پاد در دستیابی به منابع مورد نیاز، باعث ورود به وضعیت Fail میشود. راهحل: تخصیص منابع پاد را بهروز کنید.
- بررسی وابستگیها: برخی از پادها ممکن است به پادها یا خدمات دیگر وابسته باشند. راهحل: اطمینان حاصل کنید که تمام وابستگیها در حال اجرا هستند و در دسترس قرار دارند.
همانطور که میبینید خیلی راهکارهای عمومی براش گفته میشه چون باید به طور دقیق بررسی کنیم که چرا پاد به درستی اجرا نشده است.
۷. مشکل NodeNotReady:
توضیحات: این وضعیت نشاندهنده این است که نود به درستی به کلاستر متصل نیست و به دلیل مشکلاتی میتواند بهطور فعال کار نکند. اگر نود نتواند api-server رو ببینه باز تو این وضعیت قرار میگیره. کلا وضعیت خوبی نیست و احتمالا مشکلی یکم جدی پیش اومده.
برخی از علتها و راهحلهای آن:
- مشکلات سختافزاری: نقص سختافزاری میتواند باعث این وضعیت شود. راهحل: بررسی سختافزار و تجزیه و تحلیل وضعیت با kubectl describe node node-name.
- بررسی پیکربندی شبکه: مشکلات مربوط به شبکه یا اتصال ممکن است زمینهساز این خطا شود. راهحل: با استفاده از دستوراتی همانند telnet و mtr بررسی کنید که آیا نود به مستر نودها و api-server دسترسی داشته باشد.
- بار زیاد: اگر نود تحت بار زیادی قرار گیرد، ممکن است به این حالت برود. یه جورایی اصلا منابع نداره که بتونه ارتباط رو ایجاد کنه. راهحل: پایش ترافیک و بار را با استفاده از ابزارهایی مانند kubectl top nodes انجام دهید.
۸. مشکل Service Unavailable 503:

توضیحات: زمانی که شما سعی کردید از طریق یک سرویس به پادها دسترسی پیدا کنید و سامانه پاسخگوی درخواست شما نیست، با این وضعیت روبرو میشوید.
برخی از علتها و راهحلهای آن:
- پادهای مرتبط غیر فعال: شاید هیچ پاد فعالی در دسترس نباشد که بتواند به درخواست پاسخ دهد. راهحل: از kubectl get pods –all-namespaces برای بررسی وضعیت پادها استفاده کنید.
- بار زیاد روی سرویس: بار بالای ترافیک میتواند بر روی استانداردهای پاسخدهی تاثیر بگذارد. راهحل: مقیاسپذیری آن را با استفاده از HPA تنظیم کنید.
- عملکرد نادرست endpoint: ممکن است که endpoint به درستی تنظیم نشده باشد. راهحل: بررسی کنید که endpoint به درستی تنظیم شده باشد و پادهای مورد نظر به صورت بکند در آن قرار گرفته شده باشد.
۹. مشکل Network Policy Denied:
توضیحات: این خطا زمانی رخ میدهد که درخواست به دلایل پایبندی به سیاستهای شبکه به دلیل تنظیمات نادرست رد میشود. البته میتونیم به صورت مشکل به آن نگاه نکنیم. این قابلیتی است که با استفاده از آن داریم جلوی درخواستهای اشتباه رو میگیریم. ولی ممکنه این مطلوب ما نباشه و اشتباه تنظیم شده باشه که در این صورت به صورت خطا میتونیم آن رو بررسی کنیم.
برخی از علتها و راهحلهای آن:
- تنظیمات محدود: اگر سیاستهای شبکه دسترسیهای کافی برای ارتباطات قانونی تنظیم نشده باشند، این مشکل به وجود میآید. راهحل: با استفاده از kubectl get networkpolicies و kubectl describe networkpolicy policy-name سیاستها را بررسی کنید.
- بررسی تنظیمات استقرار: سیاستهای نادرست یا ناکافی میتوانند مانع ارتباطات مورد نیاز پادها شوند. راهحل: سیاستهایی که اجازه میدهند ترافیک مجاز وارد پادها شود، بهروز کنید.

-
در مسیر Observability، میمیر (قسمت هفتم) توی این پست در مورد ابزار میمیر از ابزارهای گرافانا توضیح دادیم و کاربردش رو بررسی کردیم.
-
در مسیر Observability، لوکی (قسمت هشتم) توی این پست در مورد ابزار گرافانا برای مدیریت لاگ یعنی لوکی توضیح دادیم و آخرشم یه معرفی کوتاه رو graylog داشتیم.
-
در مسیر Observability، تمپو (قسمت نهم) توی این پست در مورد تریسینگ توضیح دادیم و گرافانا تمپو رو بررسی کردیم و یه معرفی کوتاه روی Jaeger داشتیم
-
در مسیر Observability، گرافانا (قسمت دهم) توی این پست در مورد گرافانا و HA کردنش و همچنین یه سری از ابزارهاش مثل alloy , incident, on-call توضیح دادیم.



