- دواپس چیه و چرا لازمه؟ اینجا در مورد دواپس و ضرورت استفاده از آن صحبت کردم.
- چطور اپلیکیشن مناسب کلاد آماده کنیم؟ و اینجا توضیح دادم که چطور میتونیم یه اپلیکیشن مناسب کلاد توسعه بدیم.
- چه عمقی از لینوکس برای دواپس لازمه؟ و اینجا توضیح دادم که کدوم موارد لینوکس برای دواپس الزامی هست که اول سراغ اون موارد بریم.
- خودکارش کن,مشکلاتت حل میشه در اینجا در مورد اتومیشن و اینکه انسیبل چیه و چه کمکی به ما میکنه صحبت کردم.
- در مسیر دواپس اینبار اجزای اصلی انسیبل تو این پست اجزای انسیبل رو معرفی کردم و آنها را شرح دادم.
- در مسیر دواپس به داکر رسیدیم (قسمت اول) تو این پست داکر رو شروع کردیم و اونو معرفی کردیم.
- در مسیر دواپس اینبار: پشت داکر چه خبره؟ (قسمت دوم) توی این پست در مورد تکنولوژی هایی که داکر ازشون استفاده میکنه توضیح دادیم.
- تست نوشتن و شروع مسیر CI/CD (قسمت اول) توی این پست انواع تست رو بررسی کردیم و با ابزارهای CI/CD آشنا شدیم و یه مقایسه بین گیتلب و جنکینز داشتیم.
- در مسیر CI/CD گیت رو بررسی میکنیم (قسمت دوم) توی این پست قبل ورود به گیتلب نیاز بود که گیت و ورژن کنترل سیستم ها رو یه بررسی کنیم.
- در مسیر CI/CD شناخت گیتلب (قسمت سوم) توی این پست اجزای گیتلب رو بررسی کردیم و با کامپوننتهای مختلفی که داره بیشتر آشنا شدیم.
- در مسیر CI/CD پایپلاین و رانر گیتلب (قسمت چهارم) توی این پست پایپلاین و رانر گیتلب رو بررسی کردیم.
- در مسیر CI/CD وریبل، گیتآپس و جمعبندی (قسمت پنجم) توی این پست وریبلهای گیتلب رو بررسی کردیم و یه معرفی کوتاه از گیتآپس و آتودواپس کردیم و در انتها یه مقدار تجربههای خودم رو در گیتلب باهاتون به اشتراک گذاشتم.
- در مسیر Observability، الک (قسمت دوم) توی این پست استک قدرتمند ELK رو بررسی کردیم.
-
در مسیر Observability، جمع بندی استک الک (قسمت سوم) توی این پست بقیه کامپوننتهای استک الک رو بررسی کردیم و fluentd و fluentbit رو مقایسه کردیم و نهایتا یه معرفی هم روی opensearch داشتیم.
-
در مسیر Observability، استک پرومتئوس (قسمت چهارم) توی این پست یه معرفی اولیه داشتیم روی استک پرومتئوس.
-
در مسیر Observability، استک پرومتئوس (قسمت پنجم) توی این پست یه مقدار کامپوننت های استک پرومتئوس رو بیشتر بررسی کردیم.
-
در مسیر Observability، استک ویکتوریا (قسمت ششم) توی این پست استک ویکتوریا رو معرفی کردیم و سعی کردیم با پرومتئوس مقایسهاش کنیم.
-
در مسیر Observability، میمیر (قسمت هفتم) توی این پست در مورد ابزار میمیر از ابزارهای گرافانا توضیح دادیم و کاربردش رو بررسی کردیم.
-
در مسیر Observability، لوکی (قسمت هشتم) توی این پست در مورد ابزار گرافانا برای مدیریت لاگ یعنی لوکی توضیح دادیم و آخرشم یه معرفی کوتاه رو graylog داشتیم.
-
در مسیر Observability، تمپو (قسمت نهم) توی این پست در مورد تریسینگ توضیح دادیم و گرافانا تمپو رو بررسی کردیم و یه معرفی کوتاه روی Jaeger داشتیم
-
در مسیر Observability، گرافانا (قسمت دهم) توی این پست در مورد گرافانا و HA کردنش و همچنین یه سری از ابزارهاش مثل alloy , incident, on-call توضیح دادیم.
-
آغاز مسیر کوبر (قسمت اول) تو این قدم به معرفی ابزارهای ارکستریشن پرداختیم و مدارک کوبرنتیز رو بررسی کردیم.
-
کوبر سینگل ( قسمت دوم ) توی این قدم در مورد kubectl , kubeconfig توضیح دادیم و تعدادی ابزار رو معرفی کردیم که به کمک اونها میتونیم یک کوبرنتیز دمهدستی واسه تستهامون داشته باشیم.
-
کامپوننتهای کوبر ( قسمت سوم ) توی این پست کامپوننتهای مختلف کوبرنتیز رو بررسی کردیم و اجزای نودهای مستر و ورکر رو دونه دونه بررسی کردیم و توضیح دادیم.
-
پادها و مدیریت اونها در کوبرنتیز (قسمت چهارم) توی این پست در مورد پاد توی کوبرنتیز توضیح دادیم و موارد مربوط به اون رو بررسی کردیم.
-
ورکلودهای کوبر و مدیریت منابع کوبر (قسمت پنجم) توی این پست در مورد namespaceها توی کوبر توضیح دادیم و انواع ورکلود کوبر رو بررسی کردیم.
-
اگه لازم شد کوبر خودش گنده میشه! ( قسمت ششم ) توی این پست در مورد سه نوع ورکلود مرتبط با scaling به صورت خودکار در کوبرنتیز توضیح دادیم.
-
نتورک کوبر (قسمت هفتم) توی این قسمت انواع سرویس توی کوبرنتیز رو بررسی کردیم و در مورد مفاهیم اینگرس و نتورک پالیسی توضیح دادیم.
-
استورج کوبرنتیز (قسمت هشتم) توی این قسمت در مورد انواع استورج توی کوبرنتیز توضیح دادیم و مفاهیم PV و PVC و Storage Class رو بررسی کردیم.
-
پراب، ریکوئست و لیمیت (قسمت نهم) توی این قسمت موارد مربوط به محدود کردن منابع کانتینر توی کوبرنتیز رو بررسی کردیم و در مورد انواع probe ها توی کوبرنتیز توضیح دادیم.
-
پاد تو نود (قسمت دهم) توی این قسمت درمورد فرآیند انتقال پاد به نود مناسب مفاهیم پیشرفتهتری مثل affinity و anti-affinity و taint و toleration رو بررسی کردیم.
-
اولویت پاد و امنیت (قسمت یازدهم) توی این قسمت در مورد تعیین اولویت برای پادها و جنبههای مختلف امنیت در کوبرنتیز توضیح دادیم.
-
کنترل دسترسی به کوبر (قسمت دوازدهم) توی این قسمت در مورد مراحل دسترسی به api کوبرنتیز صحبت کردیم و بعدش مفاهیمی مثل سرویس اکانت رو توضیح دادیم.
-
دیزاین کلاستر (قسمت سیزدهم) توی این قسمت در مورد طراحی و دیزاین یک کلاستر و روشهای مختلفی که داره توضیح دادیم و همچنین تفاوت روشهای مختلف تقسیم منابع در کلاسترها را بررسی کردیم.
-
مالتی تننسی در کوبر (قسمت چهاردهم) توی این قسمت چالشهای مربوط به داشتن چند مستاجر بر روی کلاستر کوبرنتیز توضیح دادیم.
-
هلم (قسمت پانزدهم) توی این قسمت پکیج منیجر معروف کوبرنتیز یعنی Helm رو بررسی کردیم و در موردش ویژگیها و کاربردهاش توضیح دادیم.
-
سی آر دی و اُپراتور (قسمت شانزدهم) توی این قسمت در مورد اینکه چطوری یه ریسورس کاستوم شده به کلاستر اضافه کنیم توضیح دادیم و مفهوم اُپراتور رو توی کوبر بررسی کردیم.
-
نصب کلاستر با kubeadm (قسمت هفدهم) توی این قسمت قدم به قدم نحوه نصب یک کلاستر کوبرنتیز رو با استفاده از ابزار kubeadm توضیح دادیم.
-
نصب کلاستر با kubespray (قسمت هجدهم) توی این قسمت نحوه نصب کلاستر با یه پروژه خیلی خوب به نام کیوب اسپری که یه انسیبل خفن برای ستاپ کلاستر رائه میده رو توضیح دادیم.
-
نصب کلاستر با rancher (قسمت نوزدهم) توی این قسمت توضیح دادیم که چطور با استفاده از ابزار RKE یک کلاستر کوبرنتیز راهاندازی کنیم.
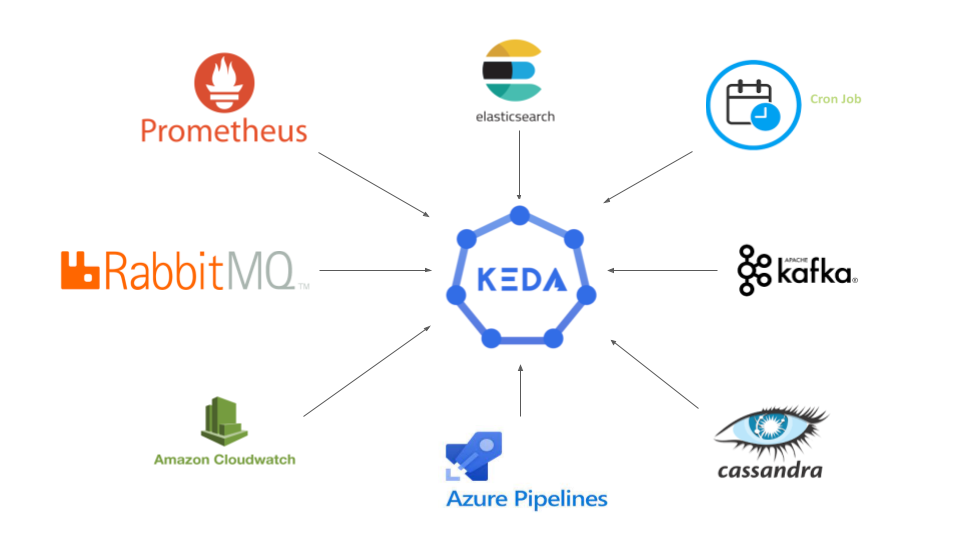
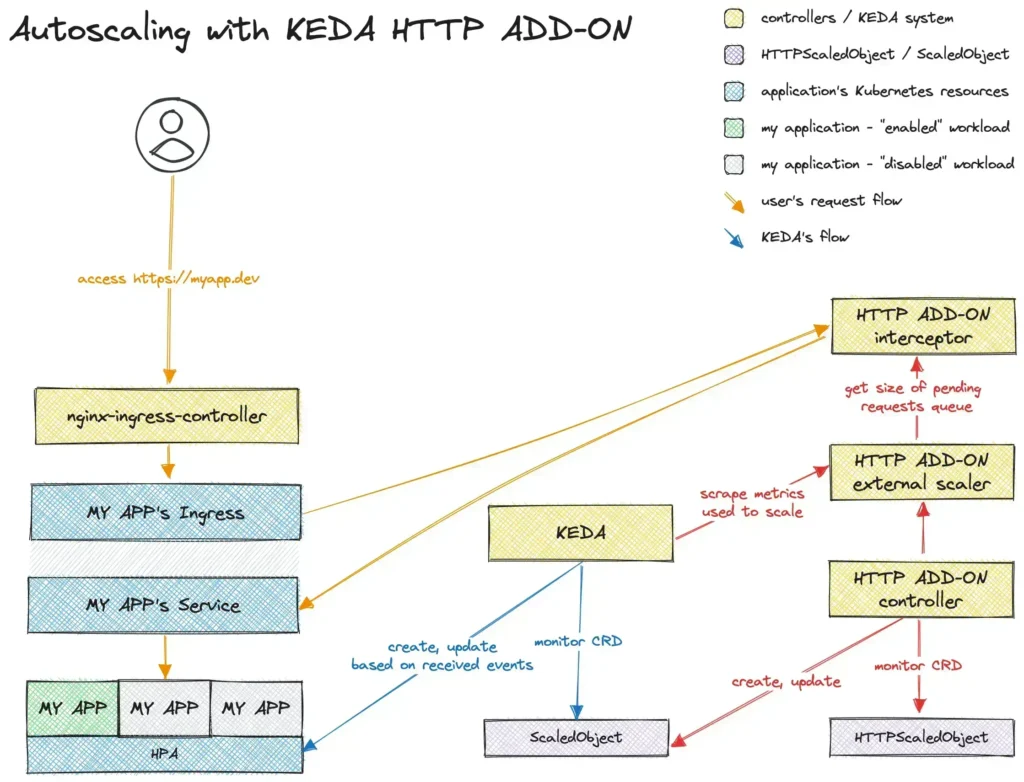
KEDA چیست؟
KEDA یک نوع ورکلود برای AutoScaling داخل کوبرنتیز است که به ما امکان میدهد تا مقیاسگذاری خودکار پادها (Pods) را بر اساس رویدادها انجام دهیم. به عبارت دیگر، با استفاده از KEDA، میتوانیم تعداد پادها را بر اساس بار کاری و تعداد رویدادهایی که به سیستم میرسد، بهطور خودکار افزایش یا کاهش دهیم. فرض کنید شما یک سرویس پردازش داده دارید که از یک صف پیام (Message Queue) پشتیبانی میکند. KEDA میتواند تعداد پادها را بر اساس تعداد پیامهای موجود در صف بهطور خودکار تنظیم کند.
چرا KEDA مهم است؟
۱. مقیاسگذاری بهینه: KEDA به ما این امکان را میدهد که منابع را بر اساس تقاضای واقعی مدیریت کنیم و از مصرف بیمورد منابع جلوگیری کنیم.
۲. پشتیبانی از منابع مختلف: KEDA از منابعی مانند Apache Kafka، RabbitMQ، Azure Queue، AWS SQS و غیره پشتیبانی میکند. این گستردگی به کاربران اجازه میدهد تا از KEDA در پروژههای مختلف با انواع نیازها استفاده کنند.
۳. سادگی پیادهسازی: نصب و راهاندازی KEDA در کوبرنتیز بسیار ساده است و میتواند به سرعت قابلیتهای مقیاسگذاری خودکار را به پروژههای شما اضافه کند.
۴. انعطافپذیری: میتوان KEDA را به راحتی با میکروسرویسهای مختلف یکپارچه کرد و حتی میتوان متدهای خودتون را برای اسکیلینگ تعریف کنید.
۵. کاهش هزینهها: با استفاده از روشهای سنتی مقیاسپذیری، احتمالاً شما پادها را بهصورت دستی و با توجه به پیشبینی بار کاری مدیریت میکنید. چنین روشهایی میتوانند منجر به افزایش هزینههای غیرضروری شوند. KEDA با کنترل خودکار مقیاسگذاری، این هزینهها را بهحداقل میرساند و از اضافه بار بر روی منابع جلوگیری میکند.
۶. تجربه کاربری بهتر: با استفاده از KEDA، شما میتوانید اطمینان حاصل کنید که سیستم شما همیشه در وضعیت بهینه قرار دارد. این کار به افزایش کیفیت خدمات و رضایت کاربران کمک میکند. به عنوان مثال، در زمانهای پیک، KEDA میتواند تعداد پادها را بهگونهای تنظیم کند که کاربران بهراحتی به خدمات دسترسی داشته باشند و از بروز مشکلاتی چون زمان بارگذاری طولانی جلوگیری کند.
۷. توانمندیهای پیشرفته: KEDA امکان تعریف چندین Trigger را فراهم میکند، به این معنی که میتوانید مقیاسگذاری را بر اساس چندین معیار همزمان انجام دهید. این امر به توسعهدهندگان اجازه میدهد تا سناریوهای پیچیدهتری را پیادهسازی کنند و سیستمهای خود را بهینهتر مدیریت نمایند.
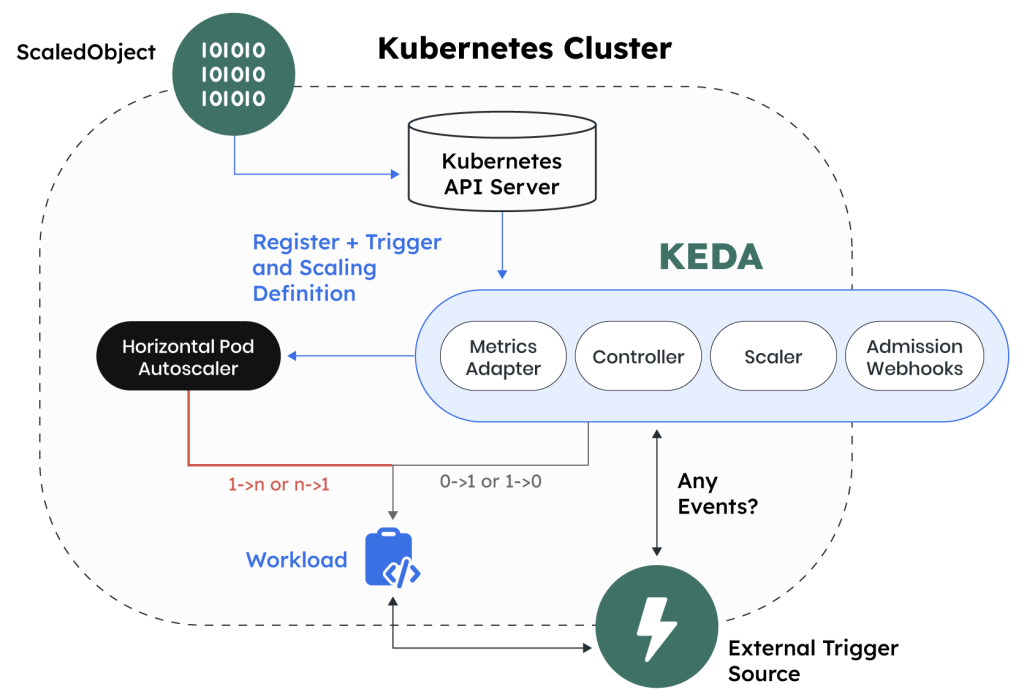
نحوه کارکرد KEDA
KEDA به کمک یک یا چند “اسکیلر” (Scaler) کار میکند که به منابع مختلف متصل میشوند و وضعیت بار کاری را بررسی میکنند. وقتی که بار کاری به یک سطح مشخص برسد، KEDA میتواند تعداد پادها را تغییر دهد. مثلاً اگر یک صف پیام حاوی ۱۰۰ پیام باشد و ما تنظیم کرده باشیم که اگر تعداد پیامها بیش از ۵۰ باشد، تعداد پادهای استفاده کننده از آن صف افزایش یابد، KEDA بهطور خودکار تعداد پادها را افزایش میدهد. این فرایند به چند مرحله تقسیم میشود:
- پیکربندی اسکیلر: شما میتوانید نوع اسکیلر را که میخواهید استفاده کنید (برای مثال، تعداد پیام در صف) تعریف کنید.
- مقیاسگذاری: زمانی که بار کاری از سطح مشخصی فراتر میرود، KEDA بهطور خودکار تعداد پادهای استفادهکننده را افزایش میدهد و برعکس، اگر بار کاری کاهش یابد، تعداد پادهای استفاده کننده را نیز کاهش مییابد.
- نظارت: KEDA قابلیت نظارت بر وضعیت پادها و بار کاری را دارد و میتواند بر اساس تغییرات، تصمیمات لازم را اتخاذ کند..
مزایا و چالشهای KEDA:
مزایا:
- کاهش هزینهها: با مقیاسگذاری هوشمندانه بر اساس تقاضا، میتوانید هزینههای زیرساخت خود را تا حد زیادی کاهش دهید.
- تجربه کاربری بهتر: با کنار گذاشتن مشکلات مربوط به بار اضافی، کاربران تجربه بهتری خواهند داشت.
- مدیریت ساده: راهاندازی و پیکربندی KEDA بسیار ساده است و نیاز به دانش عمیق فنی ندارد.
چالشها:
- پیچیدگی: ممکن است در برخی موارد، مدیریت چندین اسکیلر و منابع مختلف پیچیده باشد.
- نظارت و دیباگینگ: نیاز به ابزارها و متدهای مناسبی برای نظارت بر وضعیت سیستم و کشف مشکلات احتمالی دارید.
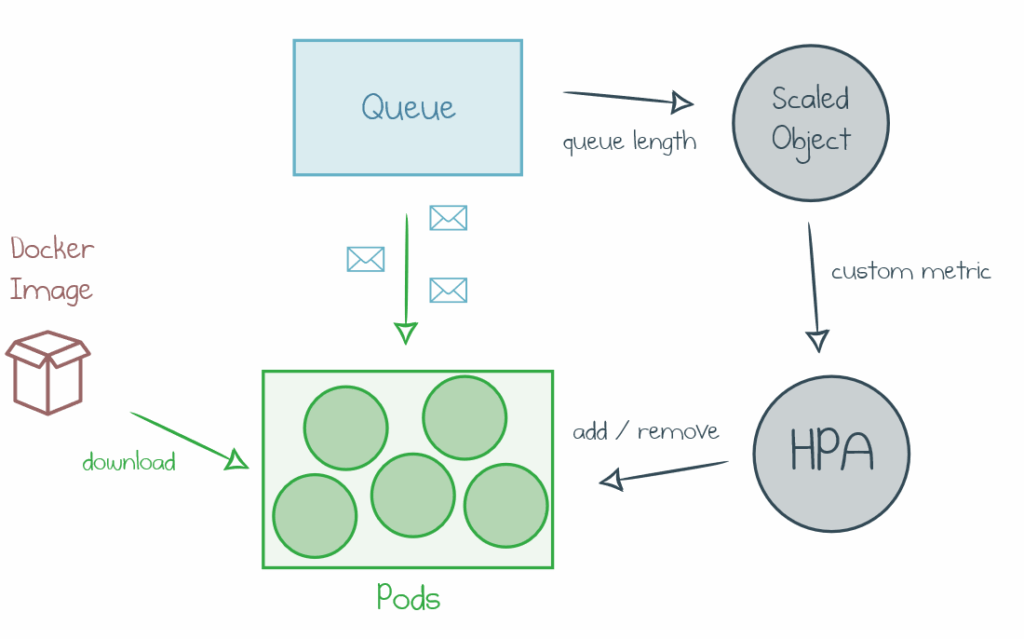
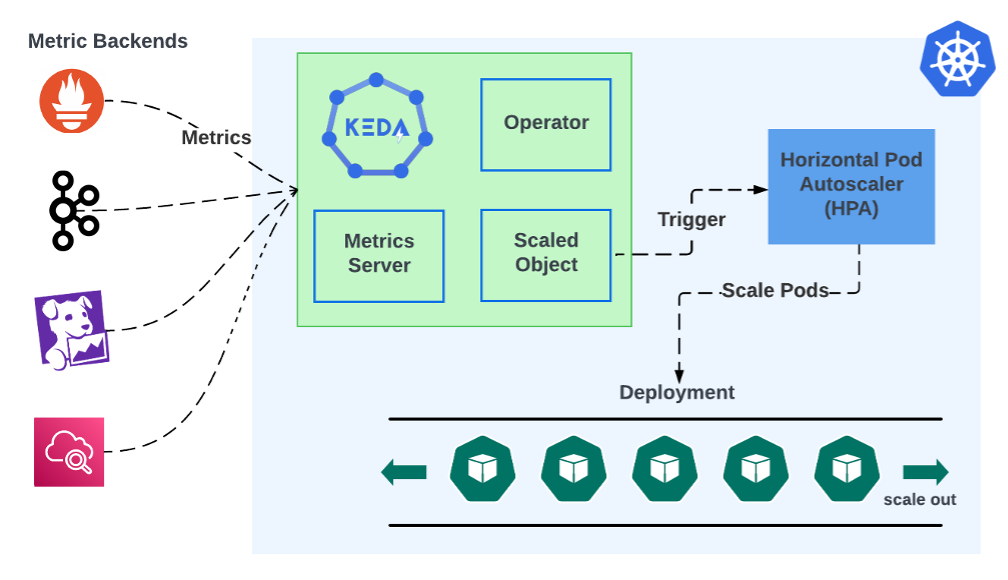
کامپوننتهای KEDA
۱. کامپوننت KEDA Operator:
KEDA Operator در واقع یک اپلیکیشن درون کوبرنتیز است که وظیفه اصلی مدیریت منابع KEDA را بر عهده دارد. این اپراتور به صورت دائمی در حال اجرا است و بهطور مداوم تغییرات وضعیت پادها، ScaledObjectها و Triggerها را نظارت میکند. وظایف KEDA Operator شامل موارد زیر است:
- مدیریت وضعیت پادها: اپراتور در صورت تغییر شرایط بار کاری، تعداد پادها را بهطور خودکار افزایش یا کاهش میدهد.
- نظارت بر منابع: KEDA Operator بهطور فعال وضعیت منابع وابسته به Triggerها را نظارت میکند و به روشهای مختلف بار کاری را اندازهگیری میکند.
- پیکربندی: این اپراتور به شما امکان میدهد که به راحتی پارامترهای لازم را پیکربندی کنید، بدون اینکه نیاز باشد مستقیماً با API کوبرنتیز کار کنید.
۲. کامپوننت ScaledObject:
ScaledObject ساختاری است که شما به عنوان کاربر KEDA تعریف میکنید تا مشخص کنید که کدام پاد باید مقیاسگذاری شود و چه شرایطی باید بر اساس آن انجام گیرد. هر ScaledObject شامل اطلاعات زیر است:
- scaleTargetRef: این بخش مشخص میکند که کدام پاد یا Deployment باید کنترل و مقیاسگذاری شود.
- minReplicaCount و maxReplicaCount: این دو پارامتر حداقل و حداکثر تعداد پادها را مشخص میکنند. به عنوان مثال، اگر بار کاری به کمترین حد خود برسد، KEDA به حداقل تعداد پادها (minReplicaCount) برمیگردد و اگر بار کاری افزایش یابد، میتواند به حداکثر تعداد (maxReplicaCount) برسد.
- triggers: این بخش شامل تعدادی Trigger است که شرایط مقیاسگذاری را تعیین میکند. به عنوان مثال، میتوان مشخص کرد که در صورت وجود یک تعداد مشخص از پیامها در صف، تعداد پادها باید افزایش یابد.
. کامپوننت Trigger:
Trigger، یا محرک، کلید اصلی عملکرد اتو اسکیلینگ در KEDA است. KEDA به کمک Triggerها تصمیم میگیرد که چه زمانی باید پادها را مقیاسبندی کند. برخی از مهمترین Triggerها عبارتند از:
- Queue Length Trigger: این Trigger میتواند با صفهای مختلفی مانند RabbitMQ یا AWS SQS کار کند. با توجه به تعداد پیامها در صف، KEDA تعداد پادها را تنظیم میکند.
- Prometheus Trigger: این Trigger از متریکهای Prometheus استفاده میکند. شما میتوانید متریکهای خاصی تعریف کنید و KEDA میتواند بر اساس آنها تعداد پادها را افزایش یا کاهش دهد.
- External API Trigger: این نوع Trigger به شما امکان میدهد که با استفاده از یک API خارجی، شرایط خاصی را برای مقیاسگذاری تعریف کنید. به عنوان مثال، وقتی یک سرویس خاص به یک Endpoint خاص دسترسی پیدا کند، KEDA میتواند پادها را افزایش دهد.
۴. کامپوننت Metrics Adapter:
Metrics Adapter به عنوان یک پل عمل میکند که اطلاعات مربوط به بار کاری را از Triggerها به KEDA منتقل میکند. این کامپوننت، دادههای جمعآوریشده از Triggerها را پردازش کرده و شرایط فعلی بار کاری را به KEDA ارائه میدهد. وظایف مهم Metrics Adapter شامل موارد زیر است:
- جمعآوری داده: اطلاعات مربوط به بار کاری از Triggerها را جمعآوری و پردازش میکند تا قابل استفاده برای تصمیمگیری KEDA باشد.
- سازگاری با منابع مختلف: Metrics Adapter فرایند جمعآوری دادهها را از منابع مختلف، مانند صفها یا متریکهای تعریفشده، انجام میدهد.
۵. کامپوننت KEDA Dashboard:
رابط کاربری KEDA به کاربر این امکان را میدهد که بهطور بصری وضعیت KEDA و ScaledObjectها را مشاهده کند. این Dashboard به کاربران کمک میکند تا به راحتی وضعیت مقیاسگذاری و بار کاری پادها را بررسی کرده و در صورت نیاز تغییراتی ایجاد کنند.
چند نمونه از استفادههای KEDA:
۱. پردازش دادههای زمان واقعی (Real-time Data Processing)
KEDA میتواند در سناریوهای پردازش دادههای زمان واقعی، مانند پردازش پیامها از صفهایی مانند Apache Kafka یا RabbitMQ، بسیار مفید باشد. به عنوان مثال:
- وضعیت: یک سیستم پردازش پیام که نیاز دارد بر اساس تعداد پیامهای موجود در صف، تعداد پادهای مصرفکنندهی آن پیام را تنظیم کند.
- عملکرد: KEDA میتواند به طور خودکار تعداد پادها را بر اساس تعداد پیامها در صف افزایش یا کاهش دهد. این باعث افزایش کارایی و کاهش هزینههای زیرساخت میشود.
۲. مدیریت بار کاربران متغیر (Variable User Load Management)
در برنامههایی که دارای بار کاربری متغیر هستند، KEDA میتواند به مقیاسگذاری پادها بر اساس تعداد درخواستهای ورودی کمک کند. مثلاً:
- وضعیت: یک وبسایت یا اپلیکیشن که در زمانهایی خاص (مانند روزهای تعطیل یا رویدادهای خاص) حجم بالایی از ترافیک وب را تجربه میکند.
- عملکرد: با اتصال KEDA به متریکهای یکی از ابزارهای نظارتی (مانند Prometheus)، میتوان بار را مدیریت کرده و با افزایش تعداد پادها در زمان نیاز، پاسخگویی بهتری به کاربران ارائه داد.
۳. تولید و پردازش رویدادها (Event Generation and Processing)
KEDA میتواند در پردازش و مدیریت رویدادها در سیستمهای مبتنی بر رویداد کمک کند. این مسئله در محیطهایی که نیاز به تولید و پردازش سریع رویدادها دارند، بسیار مفید است. برای مثال:
- وضعیت: یک سیستم پایش که باید به رویدادهای ورودی (مانند رویدادهای IoT یا تحلیل دادههای سنسورها) پاسخ دهد.
- عملکرد: KEDA میتواند تعداد پادهای پردازش به ازای هر رویداد ورودی را تنظیم کند و به شما این امکان را میدهد که به سرعت به نیازهای پردازش سریع پاسخ دهید.
۴. سناریوهای ترکیبی (Hybrid Scenarios)
در برخی موارد، ممکن است سیستمها به نوعی ترکیبی از چندین سناریوی مختلف تبدیل شوند. به عنوان مثال، یک سیستم که هم بار ورودی بالایی دارد (وبسایت) و هم نیاز به پردازش دادههای زمان واقعی (صف پیام) دارد:
- وضعیت: نیاز به پردازش همزمان درخواستهای کاربری و رویدادهای پردازش داده.
- عملکرد: KEDA میتواند با تنظیم چند Trigger مختلف، بهطور همزمان و بهینهسازی مقیاسها بپردازد.
۵. خدماتی بر بستر APIs
در پلتفرمهایی که با API کار میکنند، KEDA میتواند به بهینهسازی بارهای ورودی به این APIs کمک کند. به عنوان مثال:
- وضعیت: خدماتی که باید به حجم بالایی از درخواستهای API در دورههای خاص پاسخ دهند.
- عملکرد: تنظیم تعداد پادها بر اساس تعداد درخواستهای API، بهگونهای که کارایی سیستم به حداکثر برسد.
نتیجهگیری
KEDA یک ابزار قدرتمند و کارا برای مقیاسگذاری خودکار در کوبرنتیز است که بهخصوص در محیطهای پردازش رویداد و میکروسرویسها بسیار مفید است. با استفاده از KEDA، شما میتوانید بهراحتی بار کاری سیستم را مدیریت کنید و از منابع خود به بهترین نحو استفاده کنید. اگر به دنبال راهحلهای هوشمند برای بهینهسازی و مدیریت منابع خود هستید، KEDA گزینهای مناسب برای شما خواهد بود. با پیادهسازی KEDA، شما میتوانید بهبود چشمگیری در عملکرد و هزینههای خود داشته باشید.
در ادامه برخی از نمونههای Keda رو بررسی میکنیم:
نمونه اول: پردازش پیام از RabbitMQ
فرض کنید که شما یک سرویس دارید که پیامها را از یک صف RabbitMQ دریافت میکند و میخواهید تعداد پادها را بر اساس تعداد پیامهای موجود در آن صف مقیاسبندی کنید.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: rabbitmq-processed
namespace: default
spec:
scaleTargetRef:
name: my-rabbitmq-consumer
minReplicaCount: 1
maxReplicaCount: 10
triggers:
- type: rabbitmq
metadata:
queueName: my-queue
host: RabbitMQ-Host
queueLength: "5"# If length of queue is more than 5, scale up
نمونه دوم: مقیاسگذاری بر اساس Prometheus
در این سناریو، شما میخواهید تعداد پادها را بر اساس متریکهای Prometheus مقیاسبندی کنید. فرض کنید که متریکی به نام http_requests_total دارید که تعداد درخواستهای ورودی را نشان میدهد.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaler
namespace: default
spec:
scaleTargetRef:
name: my-http-service
minReplicaCount: 2
maxReplicaCount: 20
triggers:
- type: prometheus
metadata:
server: http://prometheus-server:9090
metricName: http_requests_total
threshold: '100'# Scale up when there are more than 100 requests
query: sum(rate(http_requests_total[1m])) by (instance)
نمونه سوم: پردازش Batch Jobs
این مثال نشان میدهد که چگونه میتوان تعدادی Job را پردازش کرد که بر اساس حداکثر تعداد jobs موجود در صف عمل میکند.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: batch-job-processor
namespace: default
spec:
scaleTargetRef:
name: my-batch-processor
minReplicaCount: 1
maxReplicaCount: 5
triggers:
- type: jobs
metadata:
jobName: my-batch-job
queueLength: "3" # Scale up when there are more than 3 jobs
نمونه چهارم: HTTP Request Scaler
فرض کنید که شما میخواهید تعداد پادهای خود را بر اساس تعداد درخواستهای API دریافتی مقیاسبندی کنید.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: http-request-scaler
namespace: default
spec:
scaleTargetRef:
name: my-api-service
minReplicaCount: 2
maxReplicaCount: 10
triggers:
- type: http
metadata:
url: http://my-api-service:8080/health
method: GET
responseThreshold: "200"#Scaleup if response time exceeds 200 ms




